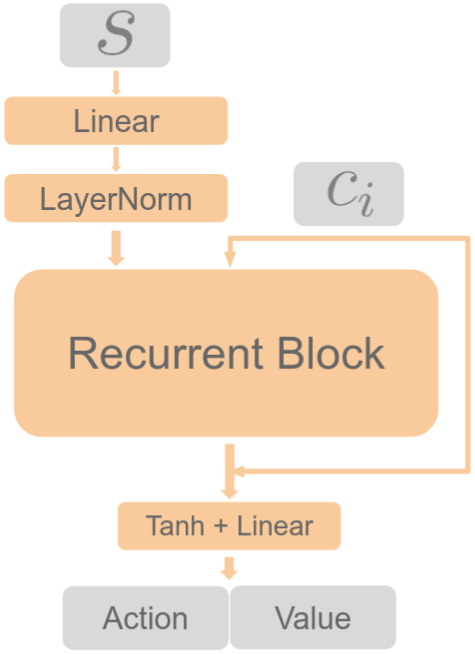
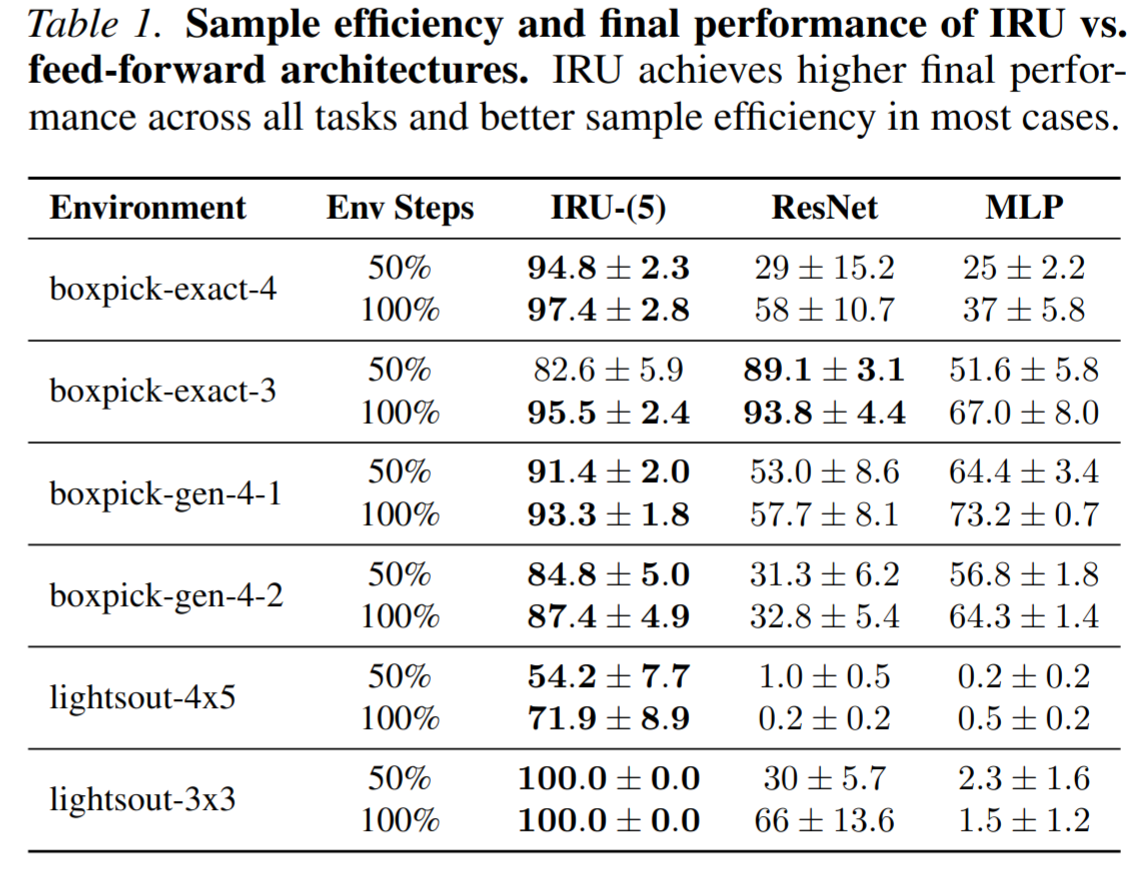
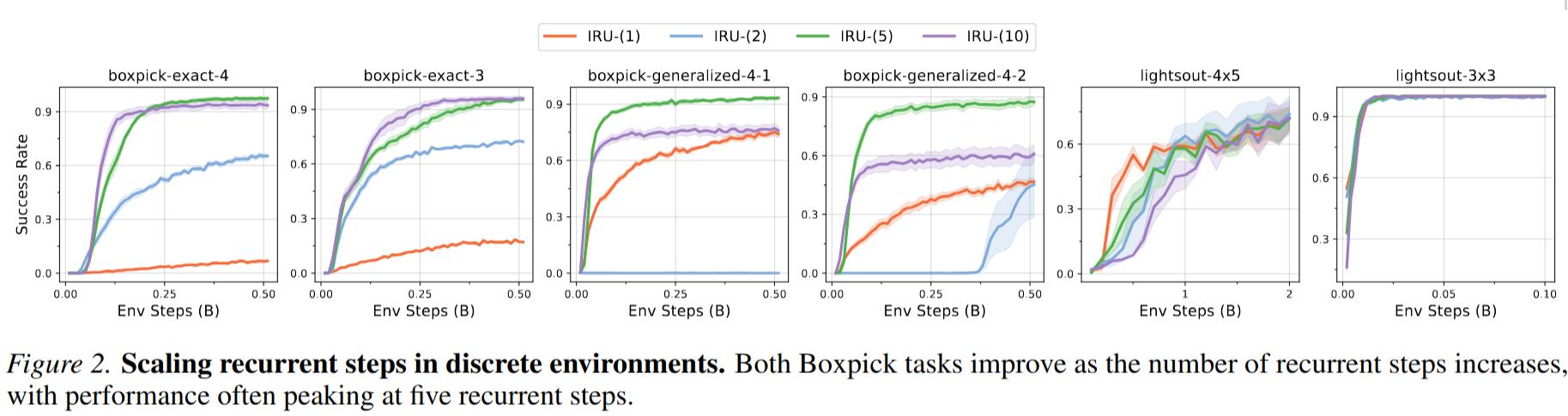
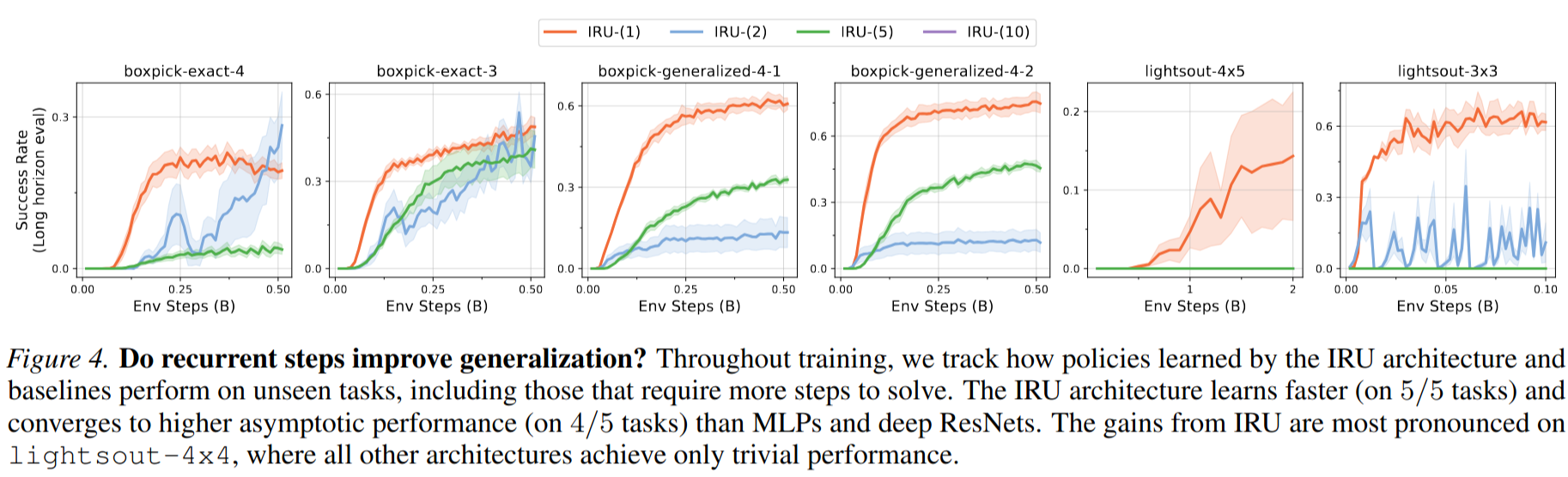
Below we present an outline and intuition for our theoretical results. Please check our paper for formal statements, assumptions and proof.

The above theorem tells us that there exist tasks on which policy classes that have more compute perform arbitrarily better than policies with less compute.
See our paper for the proof, which uses the time hierarchy theorems to construct the desired MDP.
This result is interesting because it suggests that, under computational constraints, standard results about MDPs may no longer hold.
For example, computation constraints may be reflected as partial observability, potentially explaining why prior experimental work has used non-Markov policies for solving ``fully observed'' tasks.
While recent work has argued that additional computation ("thinking" or "reasoning") is primarily useful because it enables policies to leverage multi-task pre-training, this theorem shows that the value of additional computation does not depend on multitask learning nor on pre-training.
Importantly, additional computation need not translate to larger hypotheses classes with weaker generalization. Rather, policies that use additional compute can provably exhibit stronger generalization. The intuition, which we formalize in the next theorem, is that a certain amount of compute capacity is required to represent the correct algorithm, and compute-constrained models will instead learn heuristics.

The above theorem implies that a policy class with less compute can overfit on the training tasks of a more difficult problem and
fail to generalize to longer-horizon tasks during evaluation.
A simple example of this is language models being unable to solve GSM8K problems in a single forward pass (constant compute),
but solving them when provided with more compute using chain of thought.