

Publications
Please refer to Google Scholar for a complete list of my publications.
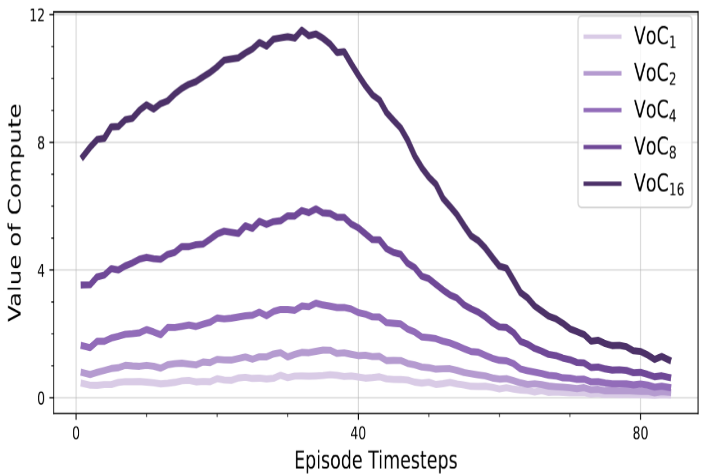
[ICML 2026; Oral, top 0.7%]
project page | paper | code
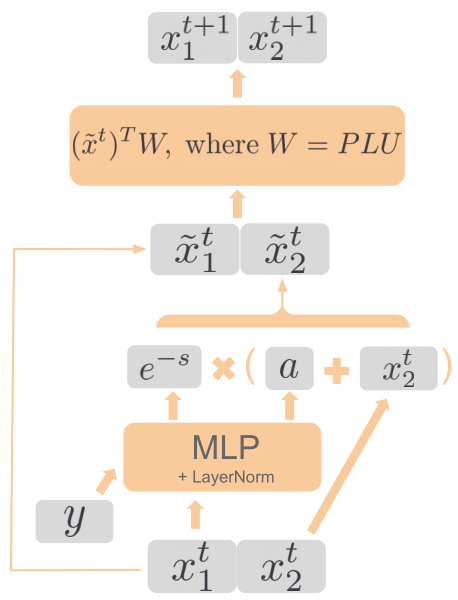
project page | paper | code
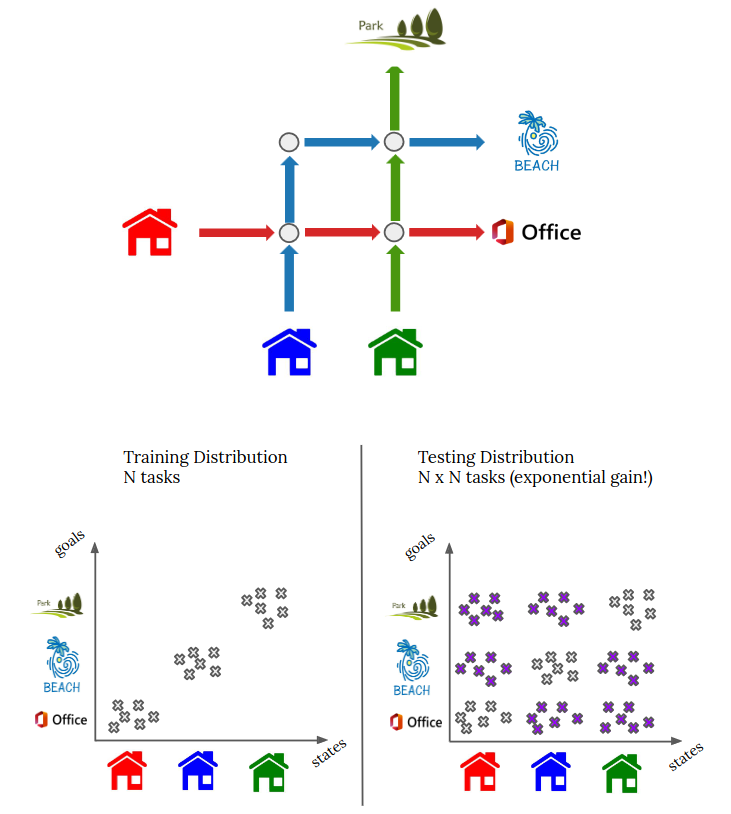
project page | paper | code
project page | paper | code
Mentoring
I have worked with the following fantastic students. If you'd like to collaborate, please drop me an email!
-
Jin Schofield (Undergraduate student at Princeton University, 2025)
Jin helped in designing tasks and implementing algorithms for BuilderBench .
-
Ahmed Turkman (Google DeepMind Scholar and Msc - AI for Science at AIMS South Africa, 2025)
Ahmed led his first ever publication at ARLET @ NeurIPS 2025 which proposed a new algorithm for unsupervised goal sampling.
Invited Talks
-
[July 2026] Princeton Visual AI lab - On the Role of Computation in Reinforcement Learning
-
[March 2026] Foerster Lab for AI Research (FLAIR) - On the Role of Computation in Reinforcement Learning
Teaching
-
Teaching Assistant - COS 597R Probabilistic Topics in Reinforcement Learning (Fall 2025)
Teaching Assistant - COS 435 Introduction to Reinforcement Learning (Spring 2026)
Last updated: June 2026.